Understanding Machine Learning Models
AI models are incredibly useful for making predictive models from various datasets. The models are however often criticized for being difficult to understand. AI models such as neural networks are often described as black box models.
Article summary: I predict the likelihood of people making more than $50,000 per year from a US census dataset. The model used is a gradient boosted tree model using the XGBoost framework and python. I analyze the model using Shapeley values to understand how the input data affects the model output.
To explore different ways to understand AI models I used the Census Income Dataset. It’s a dataset containing census information such as age, relationship status, hours worked per week, capital gain and capital loss and it can be used for the classification task of predicting if a person makes over $50,000 per year.
First we’ll have a quick look at the dataset so we know what we’re dealing with. The dataset contains
Age, continuous number
Work class, labels
Final weight (fnlwgt), the number of people the entry is believed to represent, continuous number
Education, labels
Education number, i.e. years of education, continuous number
Marital-status, labels
Occupation, labels
Relationship, labels
Race, labels
Sex, labels
Capital gain, continuous number
Capital loss, continuous number
Hours worked per week, continuous number
Native country, labels
>50K, do they make more than $50,000? True or false. What we want to predict.
It is a mix of nominal and ordinal data. For example hours worked per week or age is a continuous number and is ordinal. 20 years of age is less than 30 years of age and the values can be directly compared and put in relation to each other. The ordinal and labeled data can’t be compared in the same way, i.e. someone working as a tech support can’t be related to someone working in sales in the same way different ages could be compared.
The dataset has 32,561 entries in the training data and 16,281 entries in the test-data. The training data is used to fit the models and the test-data is used to evaluate the models using independent data.
The dataset is unbalanced because most people in the dataset make less than $50,000. For example in the training dataset 7,841 people make more than $50,000 which means that roughly 75% of the cases are of people making less than $50,000. This means that a model always predicting that someone makes less than $50,000 will have an accuracy rate of around 75% and we should aim to beat at least that.
For the task of predicting income I’m using XGBoost which is a contemporary and high-performing framework for tree-based gradient boosted models. The model it uses is in essence an ensemble of decision trees. It is not necessary to deeply understand the implementation. What is important is knowing it is a useful model for many classification and regression tasks.
The code for fitting an XGBoost model is below. the X- and Y-variables contain the dataset input and solution labels respectively for the training and test datasets. I’ve already encoded labels into unique numbers (e.g. “sex” is “0” or “1” instead of “male” or “female”). I’m only including the central parts of the code, see the github repo for more details.
import numpy as np
import xgboost as xgb
"""
Train and evaluate xgboost on the test_dataset. Returns the fitted boosted model.
"""
def run_xgboost(X_train, Y_train, X_test, Y_test):
# Prepare xgboost datasets. See the github repo for the implementation of the custom functions here
dtrain_svm = create_svmlight_datasets(X_train, Y_train, name='dtrain.svm')
dtest_svm = create_svmlight_datasets(X_test, Y_test, name='dtest.svm')
# Setup and fit the model on the training data
param = {
'max_depth': 30, # the maximum depth of each tree
'eta': 0.25, # the training step for each iteration
'objective':'binary:logistic', # output is a binary-class probability
'num_class': 1} # the number of classes that exist in this datset]]
num_rounds = 100 # the number of training iterations
bst = xgb.train(param, dtrain_svm, num_rounds)
# Get the test predictions
# Convert the predictions from fractional values to boolean values
bool_preds = np.asarray([int(np.round(line)) for line in preds])
# Print test accuracy
print(f"Model has {np.sum(bool_preds==Y_test)/len(bool_preds)*100:.3} % success rate")
# Return the fitted model
return bstThis model achieves an accuracy of about 85% on the test data so it’s at least better than the 75% benchmark model of just predicting income less than $50,000 for all cases.
Now that we have a fitted model we’d like to being understanding how the model interprets the data and which features in the data is important for making the predictions. Since the XGBoost model is tree-based it’s possible to analyze the tree structure and in which way the samples branch. There are three metrics which are typically used for looking at feature importance for this type of model.
Gain: a measure of the improvement in overall model accuracy by using the features. A high value implies that feature is important for making a prediction.
Cover: a measure of the relative number of observations related to this feature.
Weight: how many times the feature appears in the model.
Of these gain is regarded as the best choice of these metrics to look at feature importance. Just because a feature is often split on does not mean it brings the most value to the predictions. The code below generates useful graphs of feature importances.
# Get the fitted model
bst = run_xgboost(X_train, Y_train, X_test, Y_test)
# Make plots of different importance scores
for score in ['weight','cover','gain']:
xgb.plot_importance(bst, importance_type=score, show_values=False, xlabel=score)
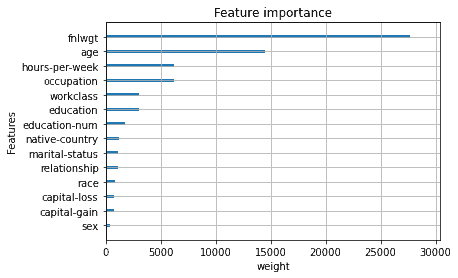
plt.savefig(f'xkb_{score}.png')Shown below is the . Final weight (fnlwgt) and age seem to be the most important features. The final weight represents the amount of people the census entry is supposed to represent and it does not make intuitive sense to me that this is the most important feature. Age makes some sense, someone older is likely to make more money but that should not be the most predictive variable, there is probably a high correlation with age but it should not be that important feature compared to many others present.
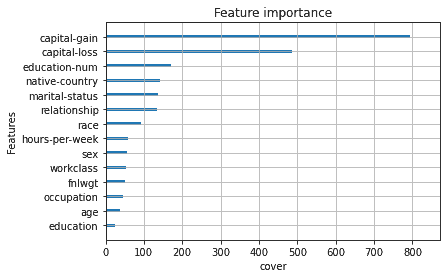
Shown below is the . Here final weight and age score quite low and instead gain- and loss of capital ranks the highest. Gain- and loss of capital were among the lowest in the evaluation of the weight metric. It makes sense that gain of capital affects the likelihood of someone making over $50,000 per year. Gain of capital is obvious and should be a good thing for the prediction of making more than $50,000 per year. Capital loss could affect it both ways, if someone loses money from their capital investments then they should make less money and are less likely to make over $50,000 per year but a capital loss could also represent that someone already makes enough money to be an active investor. Losing capital could indicate that they already make more money. From this data it’s impossible to know if it capital loss in general is good or bad for the prediction of making more than $50,000 per year.
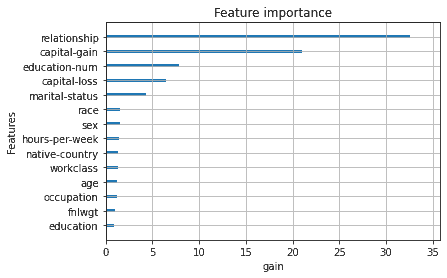
Finally we have a look at the which is regarded as the most useful metric of these three. Age scores low here as well, capital gain scores high and relationship status score the highest. Relationship status include information such as a person being married or not. I think in general people with higher income get married so this makes intuitive sense to me that it’s important. What doesn’t make sense is that marital-status is a lot less important than relationship which is a very similar variable. This seems a bit arbitrary.
Looking at these metrics I don’t feel very confident how this model behaves and I got a lot of questions why it performs as it does. Why I bring up these examples is that I want to show that these ways of analyzing the tree structure in the gradient boosting model can sometimes leave you wanting. There is however a better way of looking at a model like this to figure out which features are important and in which way they can affect the outcome.
A better way of analyzing this model is by using Shapeley values. Shapley values come from game theory but have now been applied to machine learning scenarios such as this to understand the importance of features and how they affect the model. The Shapley value is the average marginal contribution of a feature. It describes how a certain feature affects the model output compared to the mean prediction. Shapeley values can be used on a case-by-case basis to see if a feature positively or negatively affected the model output. This is done by running the prediction for that case many times by changing the inputs and looking at the marginal change depending on which feature was changed. If this is done for a lot of cases then the summarized results will give a good view on which features are important for making predictions and which way the generally affect the prediction. We could try to answer the question if capital-loss is important and if it is generally good or for the prediction of making more than $50,000 per year.
I first heard of Shapeley-values during a meteorological conference I was at in Brussels. I was prepared to do all the marginal calculations myself for this project but Shapeley values turned out to be quite popular. There exists a python library (SHAP) which is simple to use to calculate Shapeley values and to visualize analyses of different models using the Shapeley values. I’ll be using this library to analyze the XGBoost model I fit earlier.
import shap
# Get the fitted model
bst = run_xgboost(X_train, Y_train, X_test, Y_test)
# Our explainer is a tree explainer since we use xgboost
explainer = shap.TreeExplainer(bst)
# Calculate the values for the test-data using the explainer object
shap_values = explainer.shap_values(X_test)
# Visualize a summary of the Shapeley values across the test dataset
shap.summary_plot(shap_values, X_test)Running the code above produces the plot shown below. I’ve removed all nominal data except for sex since the labels are binary, 0 is female and 1 is male.
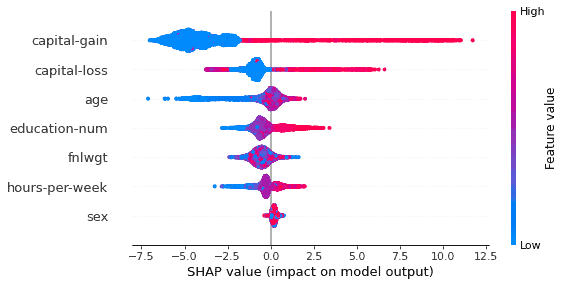
The plot above gives a clear overview of the model and how it relates to the features in the input. Each dot on the feature rows is a single case in the test-data. Blue dots are cases where that feature has a lower value and red dots are cases where that feature has a higher value. For example a red dot in the age row means that in that case the person was generally old compared to the rest of the cases. The position each dot has in the x-axis shows how for that case the feature affected the marginal output of the model. If the dot is to the left of the center then in that case that feature negatively affected the model output, i.e. made the model less likely to predict that a person makes more than $50,000 per year.
By looking at the summary plot it’s easy to see that higher values of capital gain is important for a positive prediction, generally higher values of capital loss is good, higher age is generally good for a positive prediction, longer education is generally good for a positive prediction and hours worked per week is good for a positive prediction. Since most people don’t make over $50,000 per year most of the dots are to the left of the center line. This interpretation makes sense and we can understand this model better. Even though the model is non-linear we should be able to get an intuitive understanding of the features and how the output is affected. Capital-loss is for example non-linear since it appears bimodal in the result where in some cases a higher capital-loss is quite detrimental to a positive prediction but in most cases it’s advantageous with a higher capital loss for a positive prediction.
This analysis and visualization is powerful. A drawback is however that we require more colors than blue and red to analyze the contribution of labeled categories, for occupation. We can look at a different visualization to understand how different features affect the model.
# Create a plot to see how different occupations affects the output
shap.dependence_plot("occupation", shap_values, X_test, interaction_index=None)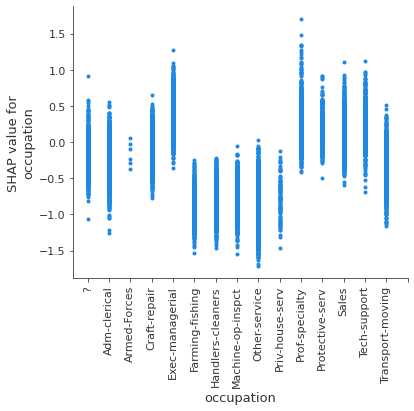
Doing this we can look at the effect a nominal feature has. For example some occupations are disadvantageous for the model predicting an income higher than $50,000 per year, such as occupations related to farming and fishing. Prof-speciality is in general advantageous for a positive prediction.
This way of understanding AI models is powerful. Even if there exists feature importance metrics used for tree-models I think Shapeley values are a better choice. We got some confusing feature importance results looking at the standard metrics but finally got more clarity by looking at the Shapeley values instead.